





本文将着重分析 FLV 容器的语法语义,结合我遇到的几个安卓平台的 FLV 加密进行分析,同时对这几个样本做解密还原。
由于许多内容是对学习的记录,所以并非一次编辑而成,可能有些逻辑问题。加上我对音视频多数内容一知半解,可能存在一些错误,欢迎大佬指出,感谢!
FLV
尽管绝大多数情况下加密方案都不会修改 FLV 容器,但了解容器的语法语义能帮助我们定位加密位置,所以这是后面的基础。
FLV 容器标准可以在 spec^01 的 Annex.E 中找到,若已经熟悉 FLV 容器可以跳过这部分。
与其他容器相比,FLV 中视频的特点是以一个完整的帧为单位的,无论这个帧是何类型或者是否包含多个 NALu/slice,一个基本单位是对一个帧的封装,当然仅有帧是无法解码的,编码参数(SPS^07、PPS^08 等)也要有,它们都在第一个帧之前;而音频可能是一到几个帧为一个单位。FLV 中的这个基本单位被称为 Tag。
容器标准
本节我们看一下标准中 FLV 容器的语法,其中大部分都能用 ReFLV^13 解析。
FLV header
FLV 文件的前 9 个字节是文件头,其中有两个标志位分别表示是否包含音频和视频:
 FLV header
FLV header对这部分使用 parse_flv_header 来解析,对应的数据类是 TAGheader;如果无法解析一般考虑是否存在其他问题,比如是否缺失文件头或者是否已被完整加密,因为单独加密文件头意义不大。
FLV body
文件头之后的就是一个接一个的 Tag + TagSize 直到 EOF:
 FLV struct
FLV struct为了方便,把 PreviousTagSizeN 看作 TagN 的一部分。一个 Tag 使用一个数据类 Tag 表示。
在一帧一个 Tag 之前,最开始的第一个 Tag 封装的是 onMetadata,它表示了容器层面的音视频信息,也是 rtmpdump 的输出信息,大多数情况下无需处理,不过也有种特殊情况:如果多个视频共用一个直播链接,比如:开始播放时画面为 720p 横向,中间换了直播设备变成 1080p 竖向,整个过程链接不变就导致它们被下载到一个 FLV 文件中,这样的 FLV 仅能播放第一小段。
在 ReFLV 中有个 splite_out() 函数可以将多段视频分成多个 FLV 文件,分隔规则为:视频使用 onMetadata 音频使用 AAC header,遇到这两种类型就写入下一个 FLV 中。
接下来的 Tag 里面封装的是初始化信息 SPS^07、PPS^08 等,这些参数优先级最高也是最重要的,一旦丢失将无法解码,因为它提供解码器所必须的解码信息。
Tag header
Tag 可以分成两部分,前半部分是 header:
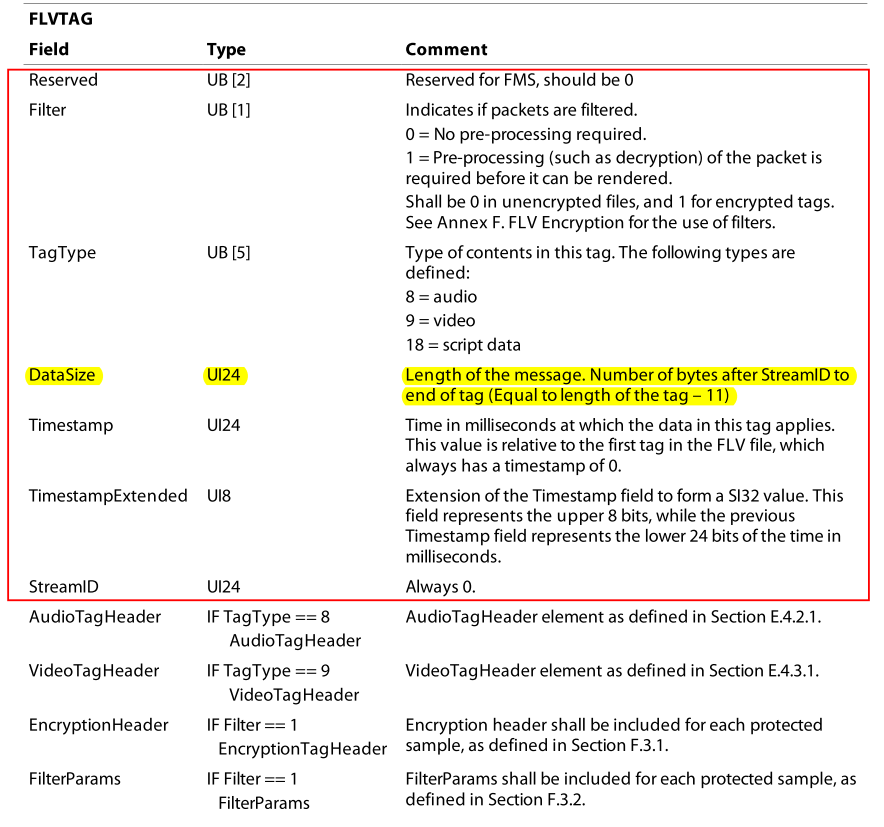 Tag header
Tag header把红框中的部分看作 Tag header 对应 Tag 数据类中的 header,使用数据类 TAGheader 表示。
这其中黄色的部分是 Tag header 之后剩余部分的大小,也就是说:可以读 11B,解析之后就知道剩余的 Tag 大小了,使用 next_tag 来实现读取过程,parse_tag_header 来解析这 11B 的内容,若做出了修改就用 build_tag_header 重新生成新的 Tag header;同样当解密完成之后需要写入目标 FLV 时,有对应的 write_tag。
另一个重要的部分是时间戳,一共 4B,又称解码时间戳(DTS),直播开始后时间戳在从 0 开始递增,但绝大多是情况下我们都是从直播开始之后一段时间才能获取到直播流,因此得到的 DTS 并非从 0 时刻开始;还有些时候会因为连麦、推流网络问题等得到错乱的时间戳。
时间戳错误会导致许多离谱的问题,比如会导致音画不同步,严重一点的造成无法播放,时间戳重叠时甚至可以隐藏一段视频,这是因为播放器会把小于当前时间戳的帧忽略,这在直播中有利于减少丢包造成的延迟累积,但 FLV 中显然会造成非预期效果;
另一方面,常用的 ffmpeg 是通过包含 Video/Audio header 的 Tag 解析结果来重置时间戳,而有时会遇到的 header 中时间戳也不正确;
更好的方法应该是选择第一个关键帧所在 Tag 作为时间戳原点,然后对音频和视频的时间戳与该原点计算偏移作为新的时间戳;之所以选关键帧,因为它是需要解码的一帧完整的画面,这与其他包含编码参数的 Tag 的时间戳不同,它的时间戳是直接影响显示时间 (PTS)。
修复时间戳对应的是 reset_timestamp。接下来的是音视频的 header。最后是包含码流的 Data:
 Tag Data
Tag Data这里的 Data 是最容易动手脚的地方,遇到的例子中都对这部分做了加密,后面再说。先看一下 Video Tag header:
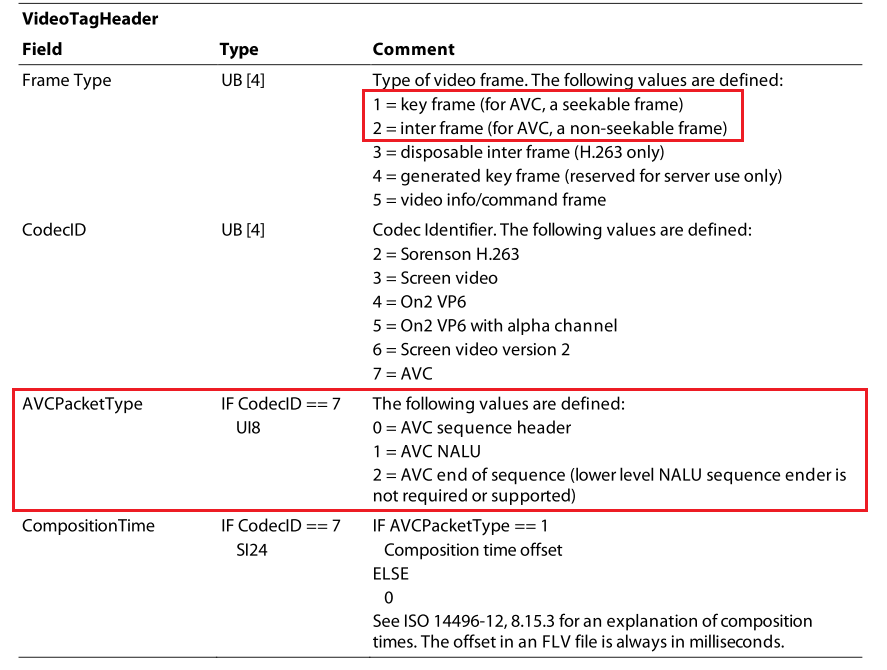 Video Tag header
Video Tag header包含了帧类型、Codec、Data 中码流类型以及相对时间戳(CTS),一帧画面的显示时间是通过 PTS = CTS + DTS 来计算的,使用 parse_video_header 来解析,解密或者修改完之后使用 build_video_header 重新构建。
跟在 Video Tag header 之后的 Data 是 VideoPacket:
 Audio Tag header
Audio Tag headerAudio 和 Video 类似:
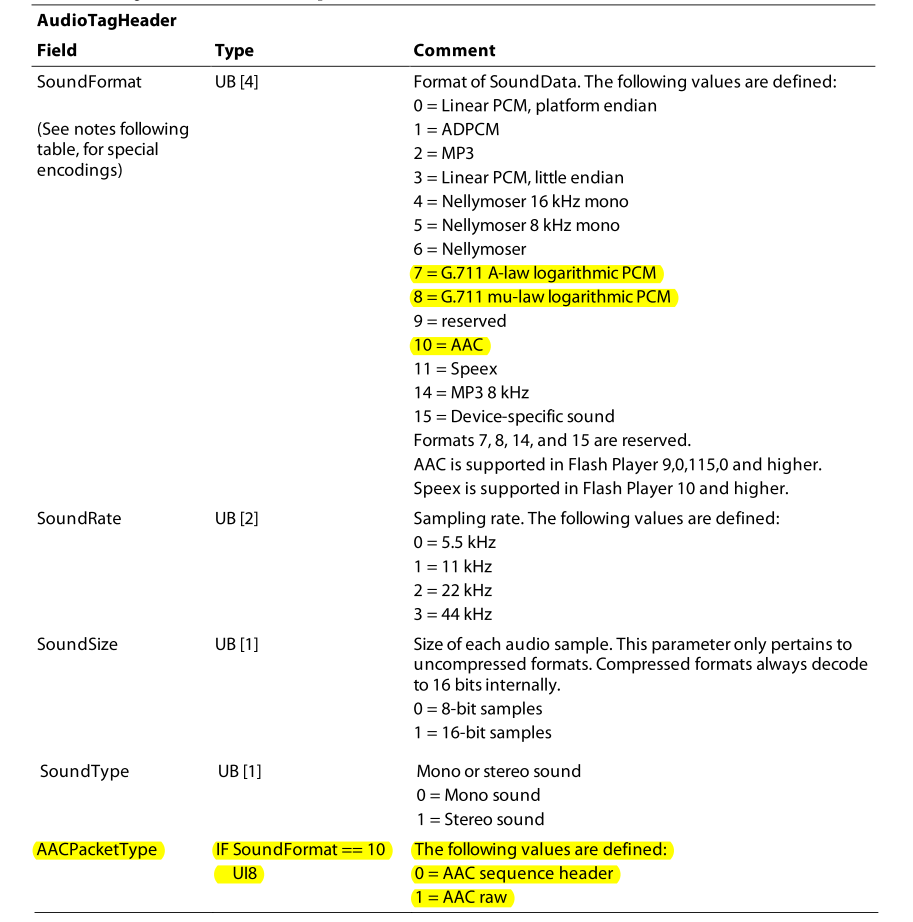 AVCPacket
AVCPacket包括音频编码器、几个参数,最后是 Data 中音频包的类型,使用 parse_audio_header 来解析,解密或者修改完之后使用 build_audio_header 重新构建。其后跟上 AudioPacket。
NALU
NALU 是网络抽象层单元缩写,顾名思义,这是为了适应网络传输和数据存储而做的码流分割,H.264/H.265 中都有它,FLV 使用的 NALu 码流语法在 ISO/IEC 14496-15 中,语法为:单元长度(4B) + NALU header(AVC:1B,HEVC:2B) + payload(RBSP),其实就是把常见的附录 B 格式中 StartCode(可以为 0x000001/0x00000001) 替换成了 单元长度(4B),其中:负载是喂给 decoder 解码的,AVC NALU header 语义如下:
 NALU header
NALU headerf(x) 和 u(x) 都是顺序读取 x 位,其中 nal_unit_type 决定负载的语法,其定义如下:
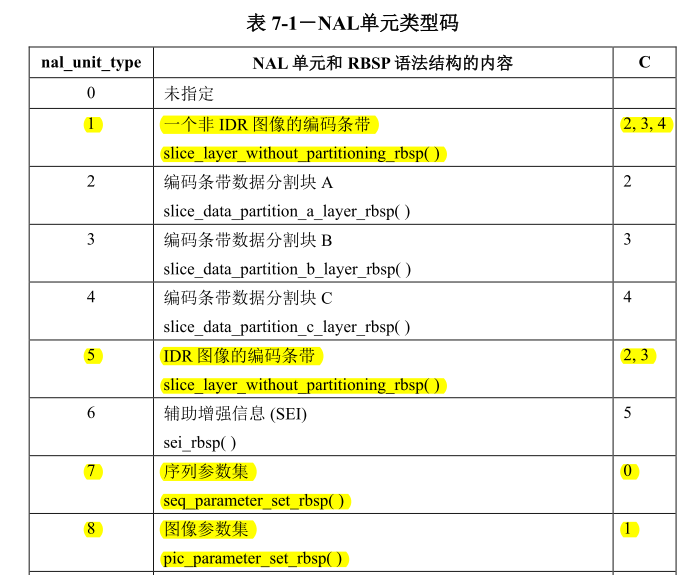 nal_unit_type
nal_unit_type其中 1 表示 IDR,5 是最常见的 I/P/B 帧,7、8 分别表示 SPS、PPS。这部分使用 parse_avc_nalu 来解析,因为一个帧可以分割为多个 NALu/slice 所以这里需要根据最开始的 4B 单元长度判断每个 nalu 长度。
HEVC NLAU header 语法如下:
 nal_unit_type
nal_unit_type一共 2B,其中 nal_unit_type(6bits) 用来标识NAL单元类型,包括参数集(VPS,PPS,SPS,SEI)以及 slice 数据如 IDR/I/B/P 等。
小结
上面这些都在标准内,截取了部分常遇到的,详细了解可以阅读标准。了解语法语义之后可以用 flvAnalyser^06 或 010 Editor + FLV.bt^10 辅助分析,比如:某 FLV 音频正常却花屏,而上述这些分析后一切正常,那可以确定 VideoPacket 一定动手脚了。
Annex.F
标准附录 F 中可以看到 FLV 的加密方案,在 Adobe Primetime SDK^09 中的 DRM 部分也可以找到对应的接口。它的 key 需要 Adobe 自家的 DRM —— Adobe Access 来分发,由于我比较菜,这种我还从未遇到过,所以就先略过该部分了。
扩展编码
FLV 自 Adobe 在 2003 年发布以来,历经 20 年的发展,已经进入耄耋之年。虽与主流的 mp4/mkv 容器比起来,FLV 并不能算古老,但它却实实在在地是一种老气横秋的容器,主因是 Adobe 不愿继续维护该标准了。但 FLV 简单轻量,而且它的头是完备无依赖的,又有良好的 Web 服务器支持,延迟更是可以做到 100ms,使其在直播场景中仍然常见。
可如今 FLV 本身支持的编码已经逐渐无法满足需求了,为了延续其生命周期,需要扩展标准来添加对新一代视频编码的支持。
HEVC
FLV 对新的 h.265/hevc 没有支持,新的编码标准压缩率更高,更加节省带宽,支持的分辨率也更高,已经逐渐成为主流,而我们要做的扩展主要是添加 video codec id 然后替换为对应编码的 VIDEOPACKET。
目前对 HEVC 常用的 video codec id 是 12,扩展标准如下:
 hevc+flv
hevc+flv该扩展由金山云提出 ksvc^02,并做了 FFmpeg 的 patch,这是最常见的扩展。
AV1/Opus
类似 HEVC,AV1 的扩展 video codec id 是 13,AV1 是 AOM 联盟开发的一种视频编码,该联盟由谷歌等大型公司主导,对标下一代视频编码 h.266/VVC,其编码复杂度相对较高,不过开源无专利费,很多云厂商都实现了该扩展,具体扩展可参考 AV1patch^03。
Opus 扩展的 audio codec id 为 9 或 13;Opus 在人声上有不俗的表现,但通用场景中,其在低码率下和 HE-AAC 相比优势并不明显,中高码率的表现又不及标准的 AAC-LC,虽然开源免费但处境尴尬,因此该扩展用的相对较少。
工具
HEVC/AV1 的扩展在 flvAnalyser^06 中有不错的支持,不过它遇到加密无法解析时会崩溃。相对而言 010 Editor 可以 Debug 模板,更容易定位问题,我对官方仓库的 FLV 模板添加了 HEVC/AV1/Opus 的支持,该模板也放在了 ReFLV^13 仓库中。
针对 HEVC 扩展,我 patch 了最新的 FFmpeg v5.1 版,又用 GitHub Action 编译了 Windows/Linux/MacOS 三个平台上的成品 minibuild^04,可以直接下载使用。此外应用 AV1patch^03 来支持 HEVC/AV1/Opus 三种扩展,但 AV1 需要 dav1d 库,需要自己在所需平台编译。
ffplay 毕竟过于简陋,有没有其他现成的播放器支持 HEVC 扩展呢,我尝试了很多款,发现 Aplayer^05 对 FLV + HEVC 有较好的支持,这款 SDK 对 FLV 容错性比主流播放器做的好很多,推荐选择一款基于该 SDK 的播放器。
FFmpeg
音视频开发中一个绕不开的工具就是 FFmpeg,俗话讲:掌握了 FFmpeg 就掌握了音视频开发的半壁江山。安卓音视频开发中更是如此,比如常见的 ijkplayer 就是基于 FFmpeg 3.4 版本的。
在对 FLV 的加解密中最常见的也是使用动过手脚的 FFmpeg 或者基于 FFmpeg 开发的工具。
下面关于 FFmpeg 的介绍具体可以参考 雷神^11 的博客中 FFmpeg 专栏,雷神千古,向雷神致敬!
Demuxer
要魔改 FFmpeg 实现加密和解密音视频帧,最直接的方法是:写入时加密,读取时解密。
这样做的好处主要是:
- 避免深入,改起来简单
- H.264/H.265 编码可以通用
- 与容器无关,FLV/MP4/MKV 等统统适用
直接看调用结构图:
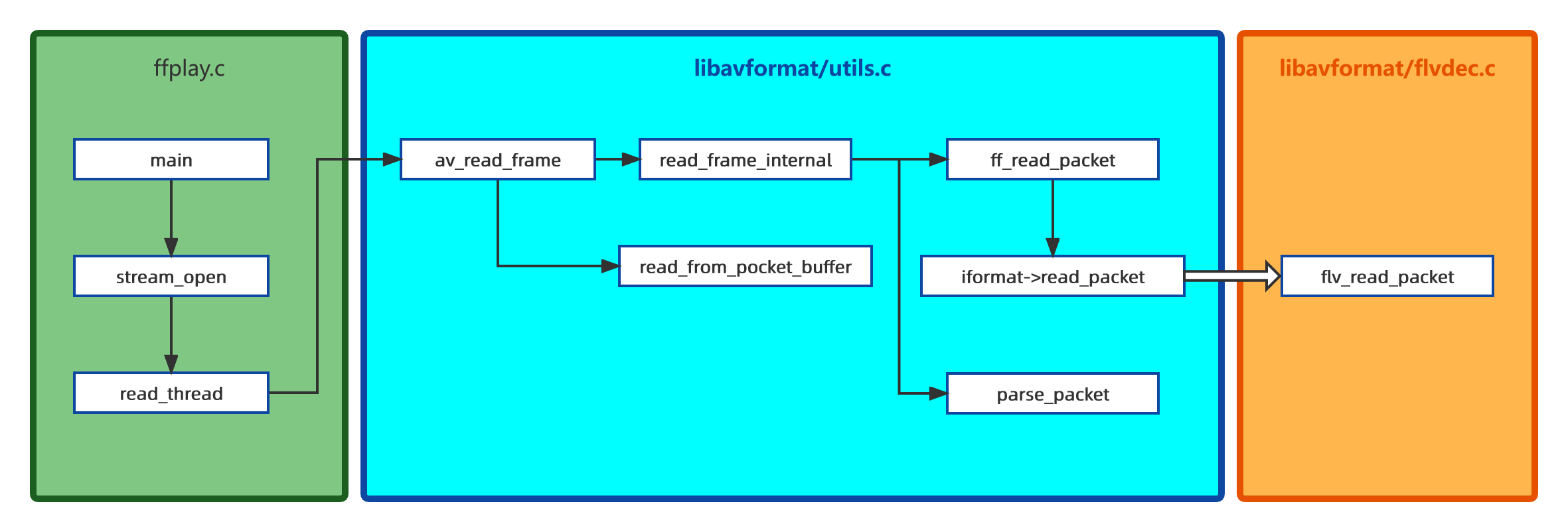 ffplay demux
ffplay demuxffplay 可类比在安卓客户端中常见的任一款基于 ffmpeg 的播放器。
read_frame_internal():封装了完整的解复用过程(demuxer),也是最容易做手脚的地方,调用它就可以得到一帧。取帧时会从 ff_read_packet() 读取,这个函数负责与 IO 打交道,如果一切顺利会判断是否需要来进一步解析,如果需要交给 parse_packet()。
flv_read_packet():负责读取读取和解析 Tag header、Video Tag header、Audio Tag header,并对 H.264、AAC 等做一些特殊处理;如果某魔改 FFmpeg 可以处理非标准 FLV 容器,那首先怀疑是否对该函数动了手脚。
实例 N
这是某收费直播系统的安卓平台,该系统的播放器基于 FFmpeg,用 C++ 开发,不开源,无混淆。抓个源下载一会,得到视频样本,试播放灰屏无声音,拖入 010 Editor 分析发现头都是完整的,符合标准未加密,推测更深层的 payload(RBSP) 加密了:
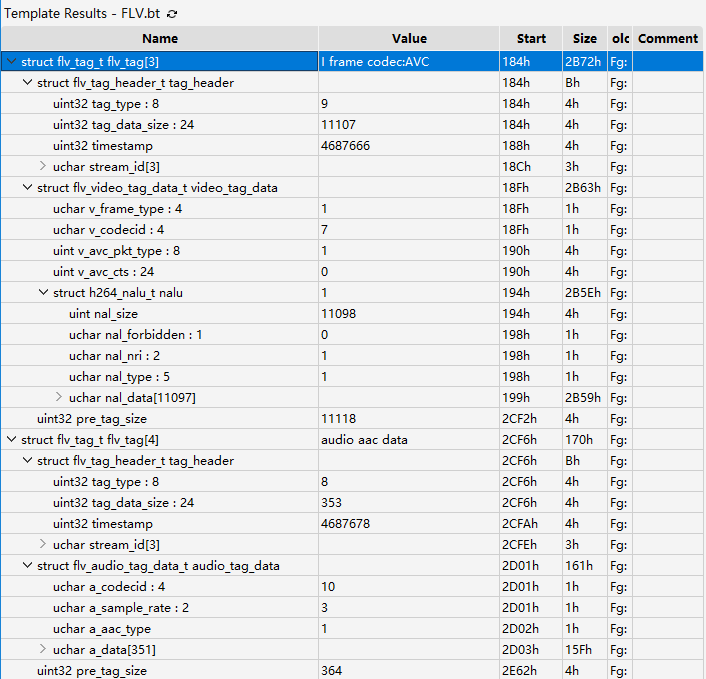 N sample
N sample接下来用 IDA 打开 N.so,因为 FFmpeg 各版本差异很大,要首先判断 FFmpeg 版本号,搜字符串 version 找到版本号为 4.1.4,从 videolan^12 下载该版本源码后用 Source Insight 打开,方便对照查看。
然后注意到导出表如下图:
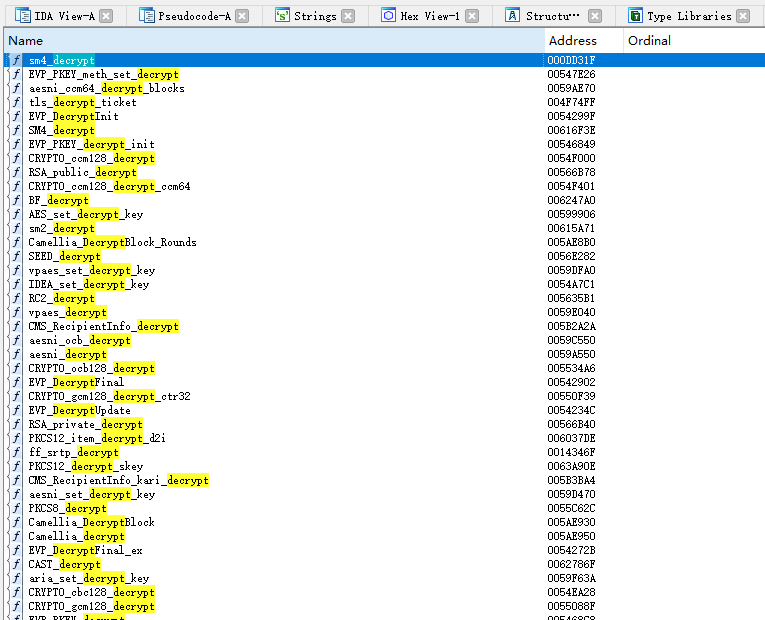 NMC export
NMC export里面包含许多种加密解密,根据分析,视频播放过程中可能存在某个解密函数被频繁调用,大胆猜测它就在导出表中,直接 trace 一下,轻易找到了它:sm4_decrypt。
由此查看调用,马上就找到 sm4_decrypt 被 read_frame_internal(AVFormatContext, AVPacket) 调用,对照源码分析如下图:
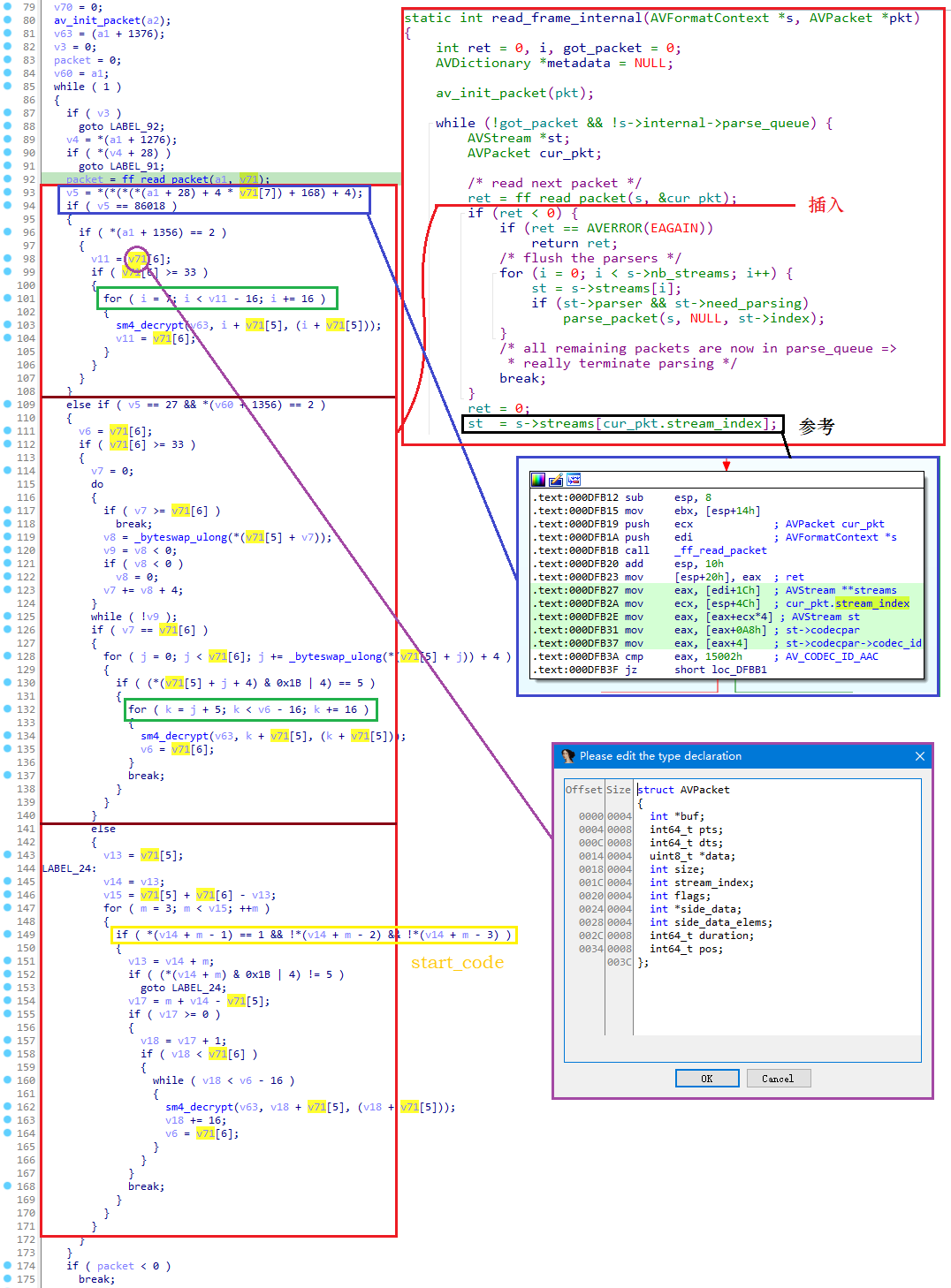 all in one
all in one红色横线是在源码中的插入位置,在 ff_read_packet() 之后交给其先解密再继续操作;
FFmpeg 有很多非常复杂的结构体,还原起来十分困难,到处都在取偏移,如果偏移比较小可以对照源码中的结构体数一下,如果很大,那只能试试可以对照着源码有没有其他位置来确定这个属性,比如:蓝色框中可以参考黑色框对应的伪代码来还原,详细内容见汇编的注释;
v71 是一个比较简单的结构体——AVPacket,可以适当修改后直接写入定义,该定义位于 libavcodec/avcodec.h 中,在 Local Types 中插入然后修改 v71 类型即可。
为了搞清楚左侧伪代码到底做了什么事情,首先分割为三部分,如图中深红线分割;
第一部分是 v5 == 0x15002,此时为 AAC,解密方式:跳过 7B,剩余的以 16B 为单位解密,最后 <= 16B 的部分保持不变;
第二、三部分都是 H264,第二部分是解密 FLV 的 NALU 码流的,第三部分解密标准中的 NALU 码流,这里只看第二部分即可;
先判断长度,然后计算 v8,v8 是 NALU header + payload,v9 是 v8 再加上 4(单元长度) 也就是 NALU 的长度,如果 v9 和 size 相同表示是 FLV 封装否则是标准封装的 NALU,之后是从 NALU 跳过 5B(单元长度 + NALU header)的位置开始解密,以 16B 为单位,最后 <= 16B 部分保持不变。
还有个问题 sm4 解密用的 key 在哪,这部分在 Java 层,略过。
通过继承可以方便的实现解密,代码:ReN^14
Parser
首先有两个名字需要区分一下:demuxer 和 parser,前者是解复用器,后者被称为解析器。解复用器的作用是从容器中把音视频流和字幕流分离出来,然后分别处理,解析器在 FFmpeg 中更多的指对 AVC/HEVC/AAC 等编码参数集的解析。
但解复用器中也有对容器的解析,这部分也可以被称为解析器。如果解析器解析的是容器,那对应的是 demuxer 的一部分;如果解析的是 NALU header 或者 VPS/SPS/PPS 等参数集,那对应的是 parser,也就是本小节的内容。
上面我们提到,读取完成之后会根据情况进行解析,解析的函数是:parse_packet,在调用的该函数的时候已经调用完 read_packet 拿到了完整的一帧数据,所以在此处既可以方便的解密整个帧,也可以在解析时针对某种 NALU 或者 NALU 的一部分做解密。
我们来看一下 parse_packet 的调用结构图:
 parser
parser前半部分是调用,动手脚的可能相对小一点,后面的以 hevc 为例,对应的解析器源码在 hevc_parse.c 中,这其中真正用于解析的是 hevc_parse 这个函数,调用了解析各种参数集的函数。
这些参数集对解码来说是必须的,如果其做了加密,必然导致无法解码。这里加密的有点是代价很小,因为这些参数集的大小相对加密 I/P/B 帧小到可以忽略。
出了参数集加密,在这里已经读完了一个完整的帧,这里加密某一类 NALU 或者 NALU 的某一部分都非常方便。这样的加密往往都放在 parse_nal_units 中。
还原
在搞实例 F 之前,先来考虑一个问题:如何还原 FFmpeg 中的结构体?实例 N 中可以看到结构体对分析至关重要,而 FFmpeg 中结构体非常复杂且分散,那如何才能更方便的还原结构体呢?
先来看一下 IDA 中创建结构体的方式:
- 直接在 LocalTypes/structs/enums 中创建结构体和枚举
- 导入头文件,要求导入的头文件无依赖
- 导入 Type Libraries,使用其中的结构体
若是使用有限几个结构体成员或结构体很简单,比如 N 中用到的 AVPacket,那直接使用第一种方法新建一个即可;若是遇到修改了 FFmpeg 结构体而产生错位,可以用占位符替代,然后一点点分析确定成员。
如果遇到的修改很多,可以考虑第二和第三种方式,但第二种方式并不适用 FFmpeg,因为其中的头文件一堆 #include,几乎无法导入成功。第三种要制作 Type Library,这需要用到 Tilib 工具,该工具在 IDA SDK 中,FFmpeg 的头文件相对容易处理一些,./configure 生成 config.h 之后问题就不大了,但在处理标准库依赖的时候难倒我了,Tilib 几乎无法处理 NDK 的 C 标准库,各种报错而且错误棘手难以找到原因,更不用谈修复了。
这时候一种思路是:能否自己编译一个带符号的版本,然后由此制作 til 呢?根据《IDA Pro Book》 8.6.2 节,有三种方法:
- 复制有符号的 til 然后导入到另一个
- 导出 typeinfo 为一段 IDC 脚本,在另一个中导入
- 导出 typeinfo 为 .h 头文件,用 Tilib 制作 til
这里采用第三种,使用 Tilib 工具的好处是可以修改头文件也可以指定编译器信息,更加灵活。IDA 导出的头文件很可能无法直接给 Tilib 使用,需要自己修改一下,常见的问题:去掉重复 typedef,声明一些结构体等等,通过报错可准确定位。
为了后续方便,我制作了 ijkplayer v0.8.8 armv7a 的符号库:ijk.til,因为 F 中已经确定魔改自 armv7a 所以可以直接导入,如果不是基于 ijkplayer 或者 armv7a 可能会导致 long 尺寸、对齐方式、结构体不同,需要 Tilib 指定编译器信息或者重新编译制作类型库。
实例 F
这是个很喜欢动手动脚而且都改的乱七八糟的 App,播放器是基于 ijkplayer.so 魔改的 F.so,推流服务也是各种魔改,所以算是个孤例吧;该魔改 F.so 也实现了 FLV 的 HEVC 扩展,而且解密和 H264 类似,下面以 HEVC 解密为例。
App 加了个梆梆免费版,脱修之后可以 hook,直接从 tcpdump/wireshark 中抓个源,下载个样本视频,播放有声音无画面,用 010 Editor 打开,如下图:
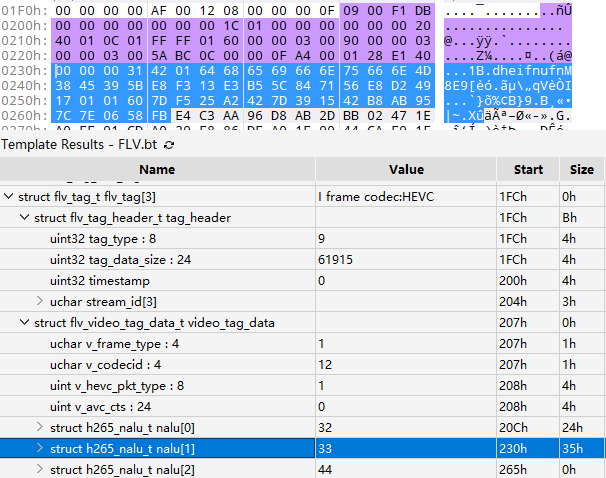 010 parse
010 parse图中紫色部分包括 Tag header,Video Tag header 以及第一个 NALU,这些都是正常的,可以正常使用模板解析,但第二个 NALU 就出错了,问题应该出在这里。
IDA 中拖入该 so,搜索字符串 ijk 确定版本号,下载 Bilibili 维护的对应版本 FFmpeg,在 Source Insight 中打开。
根据导出表,有个 decrypt() 函数很可疑,hook 一下确定了该位置是用于 AVC 解密的,函数如下:
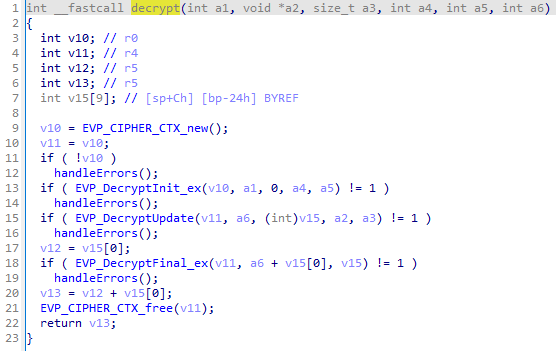 fun decrypt
fun decrypt调用了 OpenSSL 来解密,猜测 HEVC 的解密也用到了这几个 OpenSSL 的函数,查找引用,找到了 sub_F3FAC,这个函数只有一个调用者:sub_F4024,根据其中的字符串在 Source Insight 中查找,基本可以判定该函数为:hevc_parse(),显然是对解析器动了手脚,插入位置在:
 hevc_parse
hevc_parse导入 ijk.til,下面还原 hevc_parse 的参数类型,代码的可读性就非常高了,如下图:

先寻找 sign_hevc 标志,在 0,40,41,42,47 位置上寻找,标志前的不做变动,然后在模式串上做一些乱七八糟的操作得到两个固定串,分别作为 key,iv 用来做第一次解密:

密文长度为 0x13B,解密后直接保存到密文的位置,解密出来的内容作为以后解密的参数,其前 2B 用作长度,表示未加密长度,中间 1B 无用,后 16B 用作第二次解密的密钥:
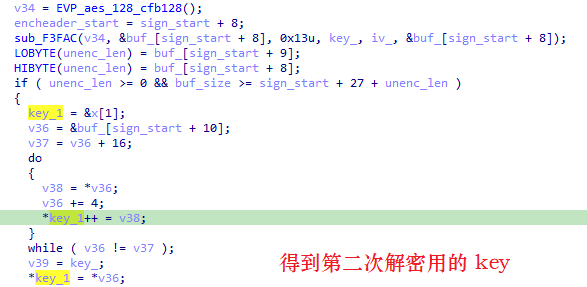
最后解密:

由上总结该加密的 NALU 语法为:[reserved_data][sign_hevc(8B)][enc_header(0x13B)][unenc_data][enc_data]。
这样 NALU 的解密就可以写出来了,AVC 和 HEVC 类似,不赘述了,感兴趣直接看代码吧 ReF^15。
Decoder
TODO: 需要样本
Filter
为了描述方便,这里的滤镜含义包括 FFmpeg 提供的和自定义的所有直接对 AVFrame(可用来存放 YUV) 的操作。
与其他类型的加密不同,如果应用了某种滤镜,那首先要解码拿到 AVFrame,然后还原,再送去编码封装才能还原画面,也就是说需要重新编码,只能拿到 rip。
另外添加滤镜的画面也可能与原画面之间存在某种联系,比如:亮度变化明显的区域在添加滤镜之后可能依旧会出现类似变化。因为滤镜作用的是 AVFrame,应用滤镜之后的 AVFrame 会发送给 encoder 编码,而编码是有损的!因此不能对 AVFrame 加密,这就导致只能对其做一些简单的映射然后播放时还原,这会使其编码后的视频保留有原视频的一些特征。
我看过一个平台,但很可惜目前其已停止运行,so 也找不到了,它可能采用了这样的方式:大致为:把 YUV 分成等宽的 10 个条带,对这其打乱顺序,这部分对解码后 YUV 进行操作;编码之后的画面自然也是乱序的,在播放器的实现中,解码拿到 YUV 之后将它们的顺序恢复。
实测
虽然没有样本,不过思路有了,根据思路我自己实现了一个,并对其进行了还原,在调用 avcodec_send_frame() 之前做打乱顺序的操作,核心部分如下:
1 | // 仅适用于 YUV420p,如果不是,可以加个 format 滤镜转一下 |
效果如下:
 filter result
filter result还原结果:
 filter result
filter result效果依旧带有很强的可辨识性,所以也可以实现一个更复杂的版本,比如:先对 YUV 分别做异或然后再分割为 16*8 个条带,这样就与灰屏差不多了。
使用滤镜的缺点也不小,首先不可能得到源码需要重编码,必然导致客户端画质下降;其次因为分割的原因导致画面失去连贯性,这样编码器在边界处需要更复杂的计算、更多的比特来储存信息,于是编码器效率降低了;最后这种方式更容易辨识,进而还原。我个人认为这并非一种理想的方式。
Codec
FFmpeg 自带的解码器效率一般,H264/H265 最常用的解码器是 x264/x265,尽管它们并未完整地实现标准,不过其对编解码过程做了很多优化,效率很好,所以应用最广。
解码器目前我还从未见过魔改的,可能是因为这部分足够复杂,我对此了解有限,下面介绍一种确定视频是否存在 Codec 魔改的方法:
- 首先排除掉读取和解析过程中做了魔改,若已魔改先对其修复
- 然后使用码流分析工具,比如:
Elecard StreamEye查看画面是否正常 - 如果正常或部分正常,那大概率没有魔改,更可能是解码之前的步骤没处理干净
- 如果所有宏块或一类尺寸的宏块全都报错显示不正常,那应该是
Codec做了魔改
对第一步,有个判断解码之前是否存在魔改的思路:hook 函数 avcodec_send_packet() 其中的 AVPacket 结构体,输出其 data 属性的数据,然后对比下载的 FLV,如果能找到相同的数据估计没魔改,反之是做了魔改。
注
本节中介绍 FFmpeg 部分只是帮助理解实例所动的手脚,所介绍的可能只占 FFmpeg 的九牛一毛,如果想了解更多细节,可以阅读 雷神^11 的博客与 《FFmpeg 从入门到精通》 一书。
自定义实现
上一节分析了 FFmpeg 中的各个环节中容易动手脚的地方,可 FFmpeg 毕竟只占半壁江山,也会遇到不用 FFmpeg 的大佬去手撸 IO 交互、流媒体协议或者解析器的情况。比如下面这个例子。
实例 D
这是某公司开发的音视频直播 SDK,宣称全自研、跨平台、延迟极低。解码部分可用硬件解码器,其他部分全自研。我这个是安卓平台的 App,核心库为 D.so,其中包含两套接口,以较新的 V2 接口为例。
hook 一下 V2 接口中的 setUrl 抓个源,然后下个样本,用 010 Editor 打开,解析一下容器:
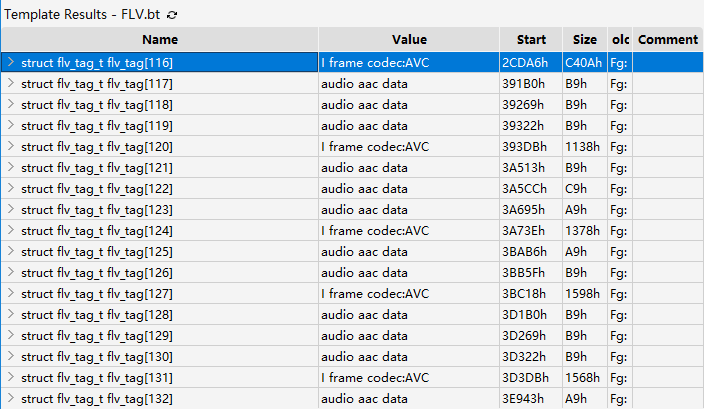 D Sample
D Sample整个文件所有视频帧全是 I 帧,这显然有问题,如何还原呢?接着看:
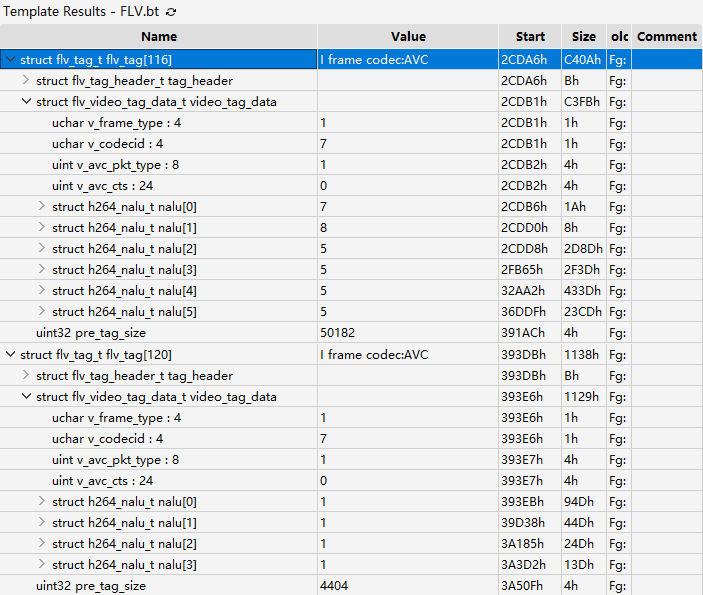 D Sample
D Sample首先注意到整个容器除了 v_frame_type 恒等于 1 外一切正常;重要的:一个 Tag 中包含多个 NALU。
Tag 116 中包含 6 个 NALU,前两个是 SPS(nal_unit_type == 7)、PPS(nal_unit_type == 8),后面四个是 IDR(nal_unit_type == 5) 帧的四个切片;Tag 120 中包含四个非 IDR 切片(nal_unit_type == 1),可以是 I/P/B 的切片,都不是关键帧;基于此,我们可以把 IDR 帧所在 Tag 保持不变,其他修复为 P/B frame(v_frame_type = 2)。
下面来刚 D.so,这里用的 Ghidra,感觉效果更好一点,流程比较复杂,要理清框架不容易,为了方便理解,我制作了一张调用结构图:
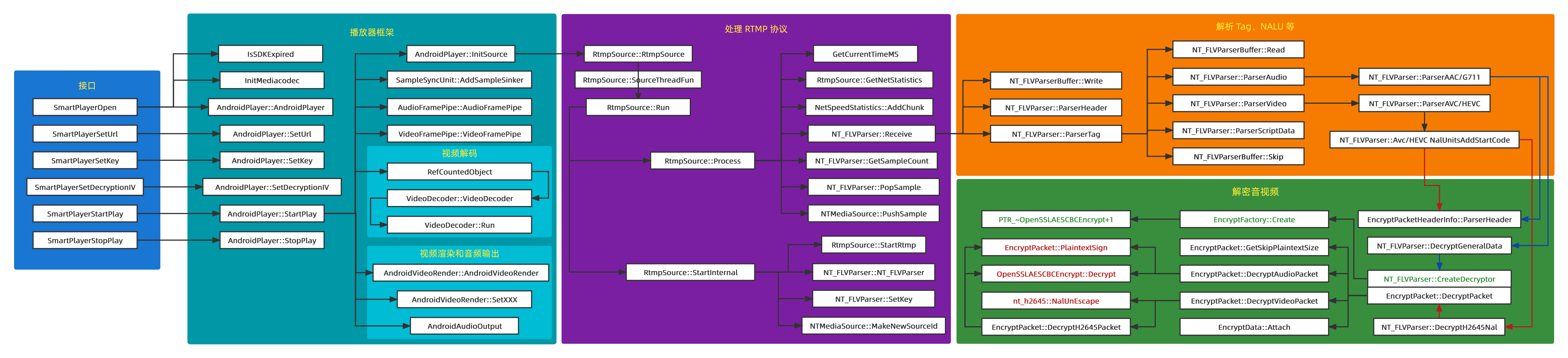 D.so
D.so前面无关紧要就不扣细节了,有些符号可以猜测函数功能,感兴趣可以去看反汇编。下面先看 FLV Parser 部分:
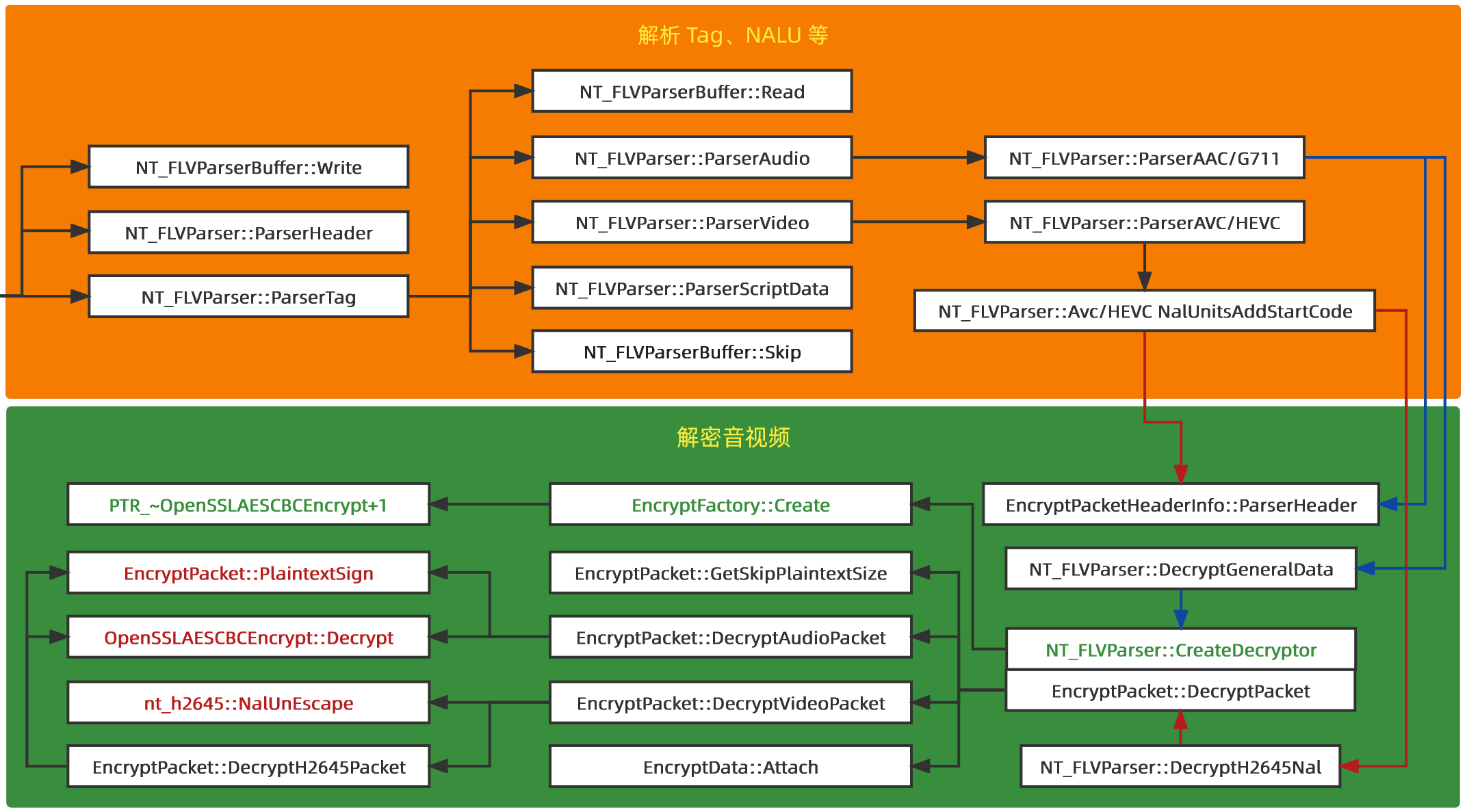 Parser
Parser是不是有种很熟悉的感觉,就是一层一层的脱掉 header 然后 parse,其间一边设置结构体一边根据值判断接下来的操作;大致过程为先处理 FLV header,然后循环 ParserTag:解析 Tag header、Video Tag header/Audio Tag header,最后音频码流直接就交给下一层,视频码流添加 StartCode 也交给下一层。这个过程和 ReFLV 类似,相当于 FFmpeg 中的 flv_read_packet。
我们把精力集中到解密音视频的具体操作,看调用流程:无论音视频都是首先调用 ParserHeader,然后创建 Decryptor 并调用 DecryptPacket 来解密,该函数首先获取一个 SkipPlainTextSize 的长度,表示未加密长度,然后分别根据音频和视频调用对应解密函数,解密完成 Attach 到结果中。
如果是音频,直接调用 AES CBC Decrypt;如果是视频,首先要 NalUnEscape,它有个逆函数是 NalEscape 负责把 payload(RBSP) 中的 0x000001 变为 0x00000301,来避免解码过程中遇到 StartCode 而产生错误,那么该函数则负责从 0x00000301 中去掉 0x03,还原真实负载之后再解密。
首先是 ParserHeader,这个 Header 在哪里呢?看下面的例子:
 enc header
enc header这里红色的 Enc header(13B) 就是需要解析加密头,接下来直接看反汇编解析就行了,这里就不看了比较简单,直接根据上图的例子解析结果如下,名称是我根据功能随便起的:
 parse header
parse header接下来无论音频还是视频都去初始化 Decryptor,主要是初始化结构体 EncryptBase:
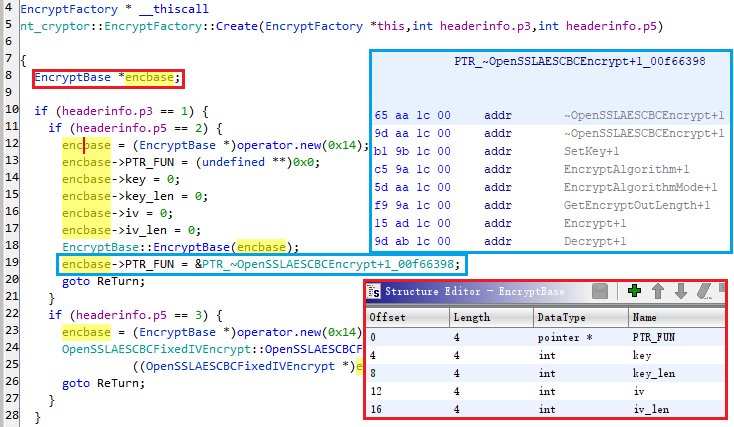 Parser
Parser根据 EncryptBase 的构造器和 get 和 set 函数可以还原红框中的结构体,PTR_FUN 指向函数指针列表,后面解密会用到其中的 Decrypt 函数;这里有四种解密:AES/AESFix/SM4/SM4Fix,根据 p3/p5 来判断用哪种,下面以 AES CBC 为例。
然后都调用 DecryptPacket 用来解密数据,如下图:
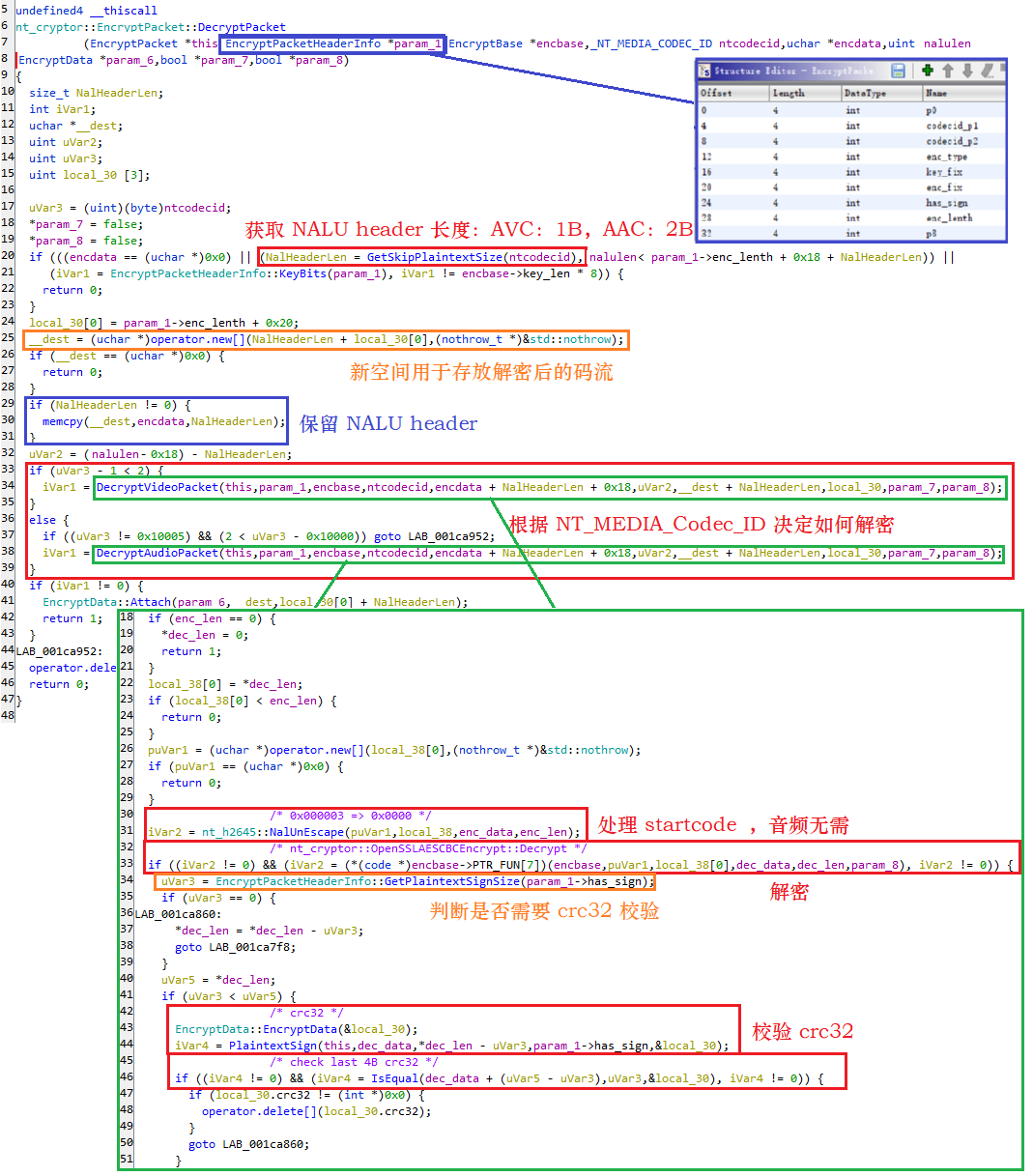 DecryptPacket
DecryptPacket这个函数标注的比较清晰了,右下的绿框中是调用 OpenSSLAESCBCEncrypt::Decrypt 之前的最后一个函数,其具体操作为:
- 做了一些检查是否满足解密条件
- 视频的话需要首先处理 startcode,将 0x000003 => 0x0000
- 根据上上图中 PTR_FUN 的赋值,调用 AES CBC 解密函数
- 解密完成后根据 p6 判断解密数据中是否带 crc32 校验,位于最后 4B
- 如果带那计算 crc32 判断和最后 4B 是否相同
至此,流程就搞清楚了,key 和 iv 是固定的很简单,就不赘述了。
实现细节见:ReD^16
小结
不像 FFmpeg 可以对照源码,确定函数作用的码流范围是件头疼的事情,可以考虑以下方式:
- hook 解密函数获取密文和明文,与此同时下载视频,然后对照获取密文偏移,从而倒推 header
- 找具有标志性的数值比如:TagType 和 CodecID 等,然后细心追踪查看内部调用的偏移
- 本例用到了一串固定字符用来标示 header,可据此确定偏移
实例 L
这是某云厂商的短视频配套 SDK,包括协议和音视频全自研,跨平台,支持 FLV 加密。但有趣的是其并未为其云上客户提供该接口,而是自家产品用上了。
首先确定做加密的位置,目标 app 中有 160 个 so,和音视频相关的有十几个,和 ffmpeg 相关的几个库 trace 了 AVFrame 相关的函数,无果,剩下的几个拖到 IDA 里看看有没有 rtmp/FLV/AES 等关键词,然后根据偏移 trace,最后找到其与 FLV 加解密相关的库是 L.so,其中实现了被称为 F1VAESC0dec 的伪编解码器来做加解密。
L.so 中没有符号,分析起来比较困难,刚不动,账号还差点被封了,吓个半死。于是转过头分析 iOS 平台,发现反汇编代码中是有这部分加密的,只是没有提供接口和说明。
SDK 中是静态库,看起来太麻烦,我就自己编译了一个带符号的 Demo 分析了一下。下面直接看一下调用流程:
TODO:分析 + 流程图 + 代码
总结
第一次搞 FLV 视频的加密与解密到现在大概有一年了,当时遇到了实例 F,但是困扰了很久,断断续续地估计搞了大半个月才搞定了大部分,其实主要是看音视频相关内容,这期间也有了这篇文章的轮廓,最开始文章是概述性的,最近我又翻出来,制作了很多新图,修改了很多内容变成了现在这种讲解性的。第一次搞定之后还是非常有成就感的,不过也搁置了很长一段时间,之后陆陆续续又遇到了其他例子,本文的内容也逐渐多了点。
有时候感觉自己集中精力搞明白一件事情之后下次总想着捡现成的,结果很久之后发现其实从来都没搞明白过。音视频不必说自然是博大精深,常学常新,而逆向总给我一种好像搞明白一件事情的幻觉,可很多时候自己基础并不扎实,那就只是空中楼阁。
期间遇到了非常多问题,感谢网络各路音视频开发大佬,也感谢给我提供样本的哥们。
